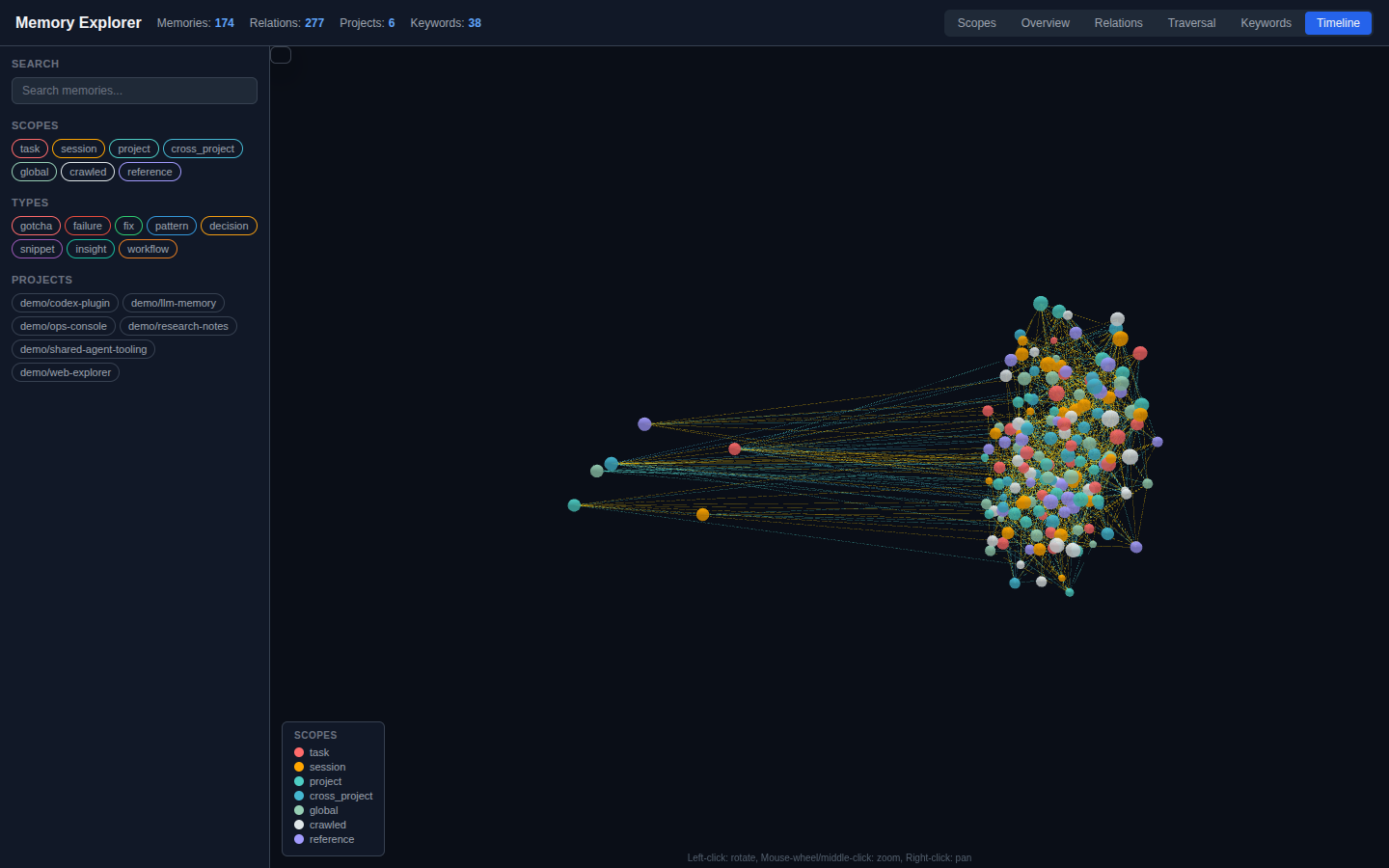
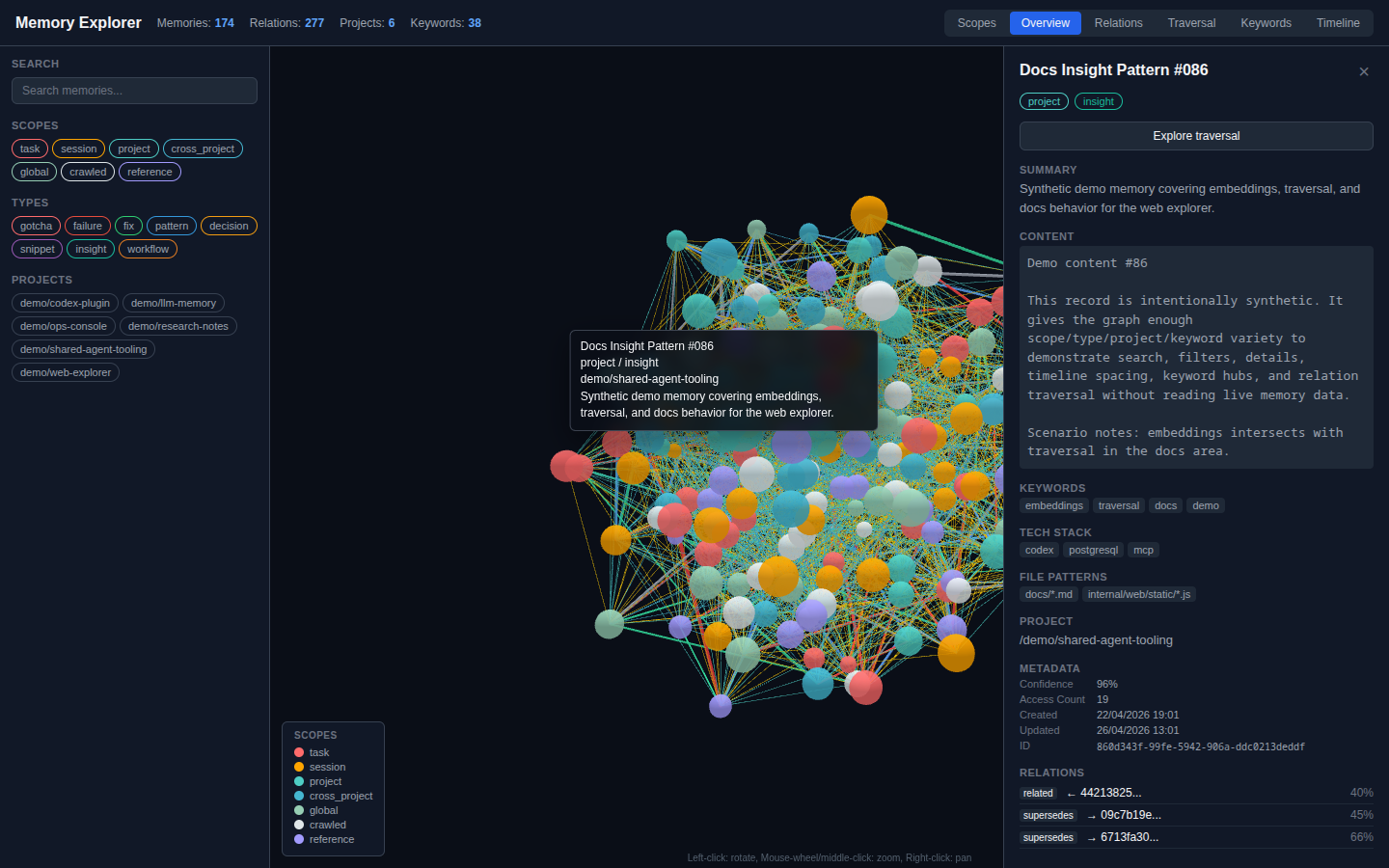
LLM Memory is a long-lived memory layer for coding agents. It stores reusable decisions, fixes, gotchas, patterns, snippets, scanned reference material, crawled session history, and cross-project insights in PostgreSQL with pgvector, while scoped working memory keeps short-lived handoff context available across restarts.
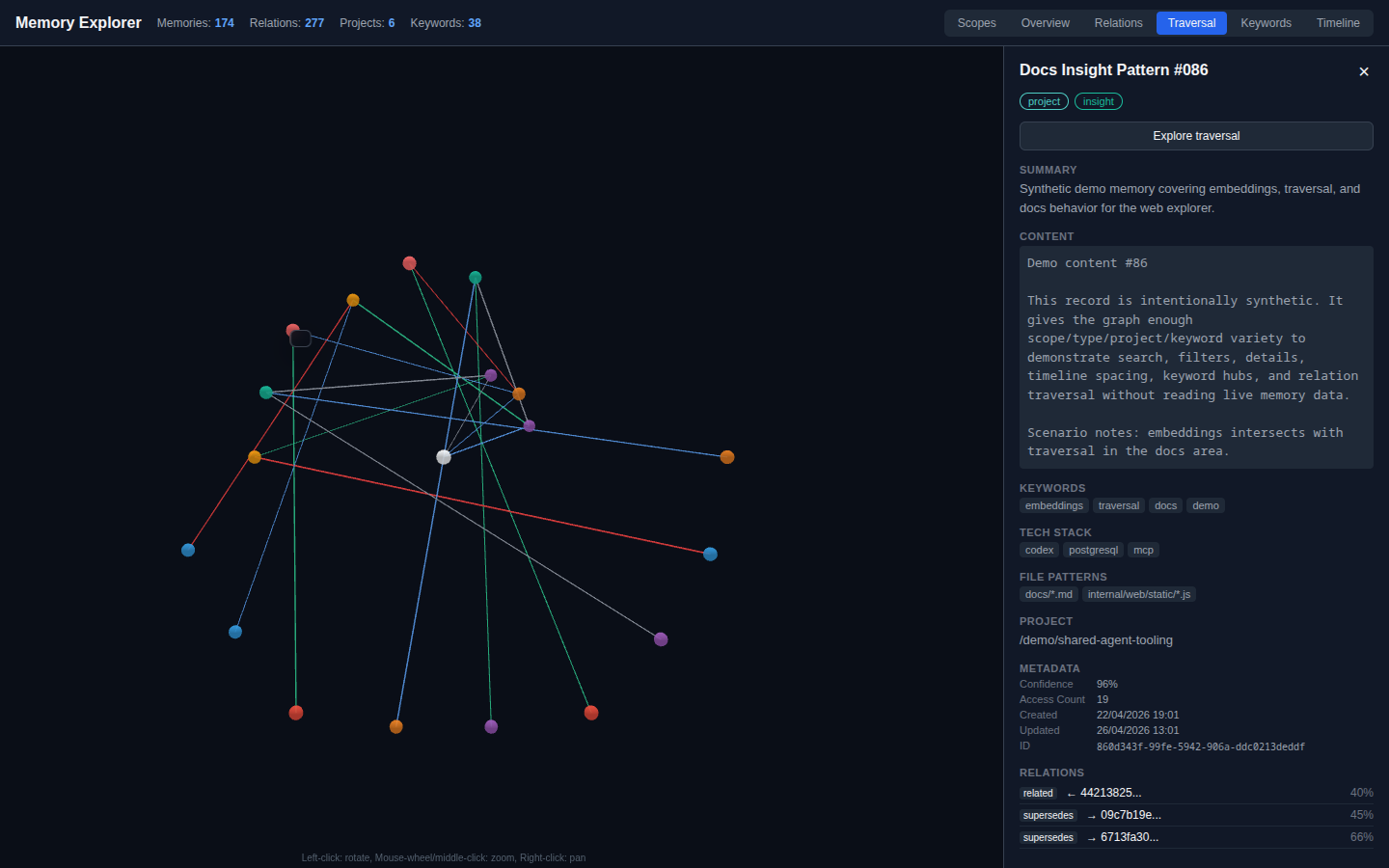
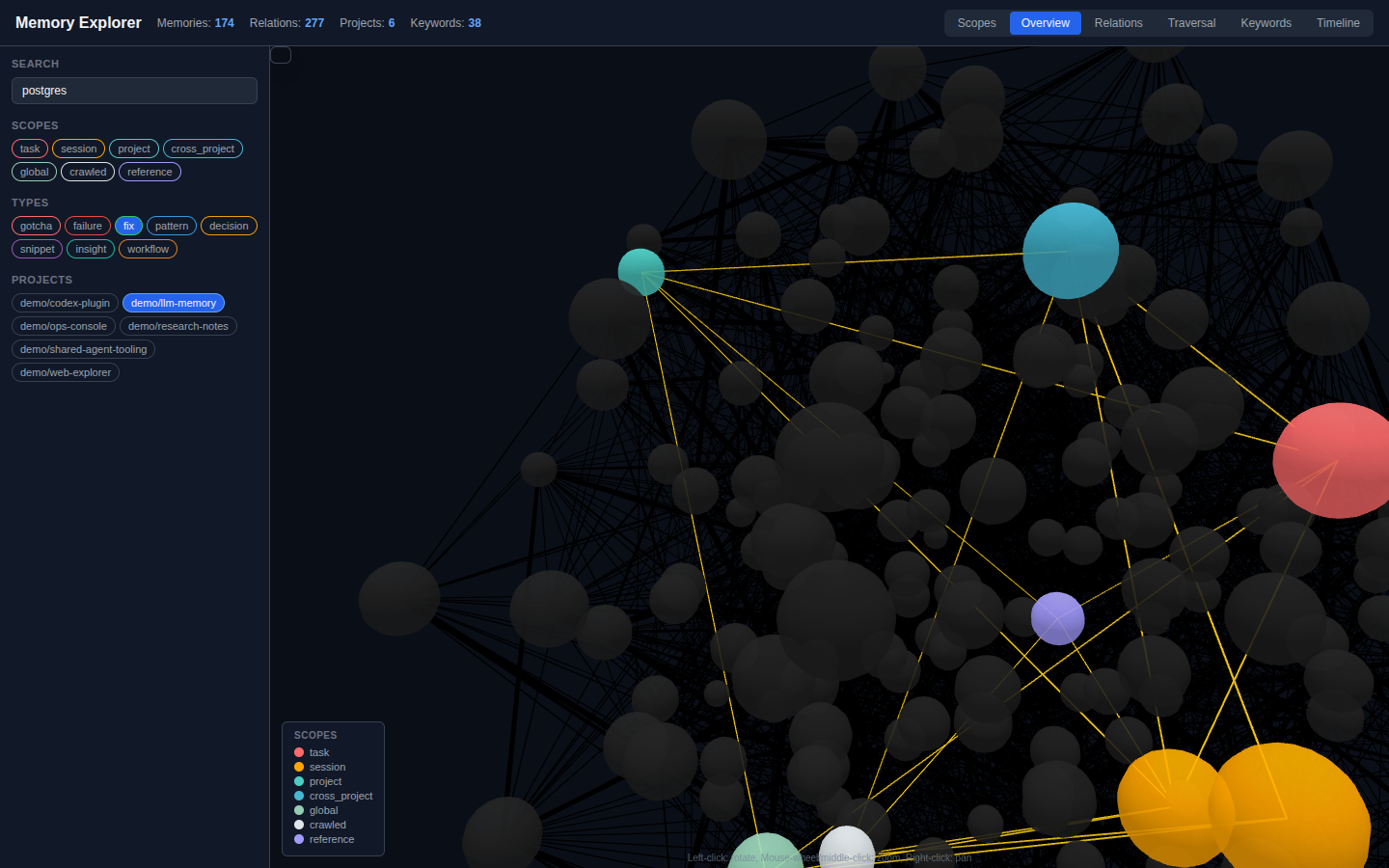
The retrieval layer now combines semantic, keyword, hybrid, contextual, hierarchical, and associative graph recall with structured fact and relation indexes, chunked embeddings for long memories, project and tech-stack filters, and optional local reranking. Agents can see why a memory matched, follow related memories, and synthesize a strategy from prior work while keyword and contextual search remain available when embeddings are still catching up.
The safety and lifecycle surface is built for real agent workflows. Transcript checkpoints stage reviewable candidates instead of silently writing durable memories, alerts remain visible until each project acknowledges them, destructive forget flows stay behind approval, and memory versions, trust metadata, non-destructive invalidation, project path migration tools, portable NDJSON import/export, and full backup verify/restore flows keep the store maintainable over time.
The operational side is equally practical: the installer configures Codex or Claude integrations, slash prompts, a Codex skill, Docker-backed Postgres, local explorer services, and user systemd startup units. A fast llm-memory doctor command checks the installed binary, database reachability, migration state, memory health, embedding provider, and installed Codex guidance without requiring a long benchmark run.
Benchmarking has grown into a dedicated regression surface. Golden, scale, adversarial, and LoCoMo suites run against isolated benchmark resources, report evidence recall, category scores, timings, reranker settings, and failure reasons, and can checkpoint long answer-and-judge runs. External Codex comparison calls are sandboxed, tool-isolated, retried, and bounded by worker pools plus subprocess recycling so benchmark experiments stay separate from the normal memory store.